26 июля 2011 г.
oracle: library cache
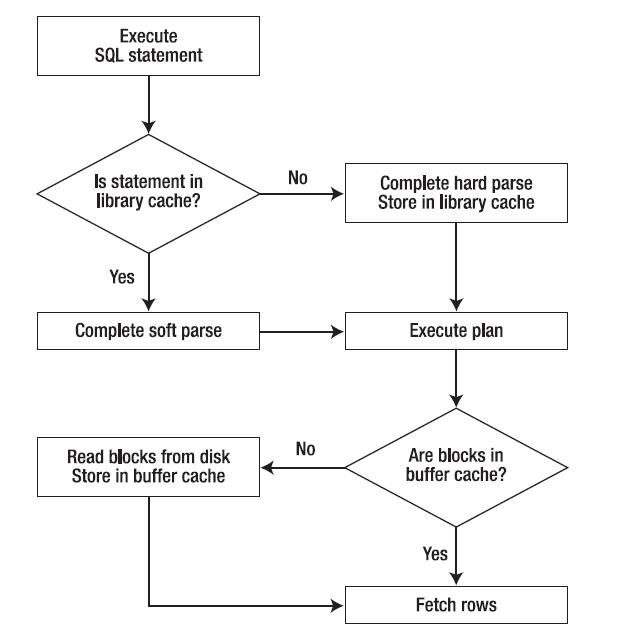
Library cache - часть shared pool, область памяти, которая содержит распарсенные выражения.
Парсинг включает в себя проверку синтаксиса выражения, проверку объектов, и проверку привелегий пользователя на эти объекты.
После Oracle проверяет есть ли уже такое же выражение, в library cache.
Soft parse - если выражение уже есть в library cache, то Oracle использует его оптимизированный вариант, его план выполнения.
Hard parse - если выражения нет в library cache, то Oracle оптимизирует выражение, строит новый план выполнения.
Соответсвенно, soft parse лучше чем hard parse с точки зрения производительности.
Посмотреть какие запросы находятся в library cache можно с помощью v$sql.
Пример. Выполним 3 вроде бы одинаковых запроса
select * from emp where deptno=10;
SELECT * FROM emp WHERE deptno = 10;
select /*comment*/ * from emp where deptno=10;
-- посмотрим что в library cache
select sql_text, hash_value, address, executions from v$sql where upper(sql_text) like '%EMP%';
--результат
Получилось 3 разных разобранных запроса.
Это получилось из-за того, что хоть запросы логически выглядят одинаково, но из-за различий в регистре и из-за комментария, Oracle распознал их как 3 разных запроса.
Парсинг включает в себя проверку синтаксиса выражения, проверку объектов, и проверку привелегий пользователя на эти объекты.
После Oracle проверяет есть ли уже такое же выражение, в library cache.
Soft parse - если выражение уже есть в library cache, то Oracle использует его оптимизированный вариант, его план выполнения.
Hard parse - если выражения нет в library cache, то Oracle оптимизирует выражение, строит новый план выполнения.
Соответсвенно, soft parse лучше чем hard parse с точки зрения производительности.
Посмотреть какие запросы находятся в library cache можно с помощью v$sql.
Пример. Выполним 3 вроде бы одинаковых запроса
select * from emp where deptno=10;
SELECT * FROM emp WHERE deptno = 10;
select /*comment*/ * from emp where deptno=10;
-- посмотрим что в library cache
select sql_text, hash_value, address, executions from v$sql where upper(sql_text) like '%EMP%';
--результат
| SQL_TEXT | HASH_VALUE | ADDRESS | EXECUTIONS |
|---|---|---|---|
| select * from emp where deptno=10 | 508465132 | 070000002C193B50 | 1 |
| SELECT * FROM emp WHERE deptno = 10 | 1243201595 | 070000002C14A328 | 1 |
| select /*comment*/ * from emp where deptno=10 | 330949115 | 070000002C143260 | 1 |
Получилось 3 разных разобранных запроса.
Это получилось из-за того, что хоть запросы логически выглядят одинаково, но из-за различий в регистре и из-за комментария, Oracle распознал их как 3 разных запроса.

25 июля 2011 г.
oracle: DELETE
1. Удалить все записи, где sal < 1000, можно двумя вариантами:
-- можно так
delete from (select * from emp where sal< 1000);
-- или "классический"
delete from emp where sal < 1000;
-- можно так
delete from (select * from emp where sal< 1000);
-- или "классический"
delete from emp where sal < 1000;
14 июля 2011 г.
oracle: Нумерация строк в запросе
Источник: Нумерация строк в запросе
Есть таблица.
Нужно последовательно вывести записи вместе с порядковым номером:
Однако если перед выводом нужно записи отсортировать (ORDER BY) по полям, тогда такой запрос не проходит, так как Оракл сначала формирует ROWNUM, и лишь потом сортирует записи.
Поэтому будем оракл обманывать таким образом:
Ну а для гурманов смотреть здесь «аналитические функции»
Есть таблица.
Нужно последовательно вывести записи вместе с порядковым номером:
SELECT ROWNUM, pole1, pole2, pole3 FROM my_table;
Однако если перед выводом нужно записи отсортировать (ORDER BY) по полям, тогда такой запрос не проходит, так как Оракл сначала формирует ROWNUM, и лишь потом сортирует записи.
Поэтому будем оракл обманывать таким образом:
SELECT ROWNUM, pole1, pole2, pole3
FROM (SELECT pole1, pole2, pole3
FROM my_table
ORDER BY pole1, pole2, pole3);
Ну а для гурманов смотреть здесь «аналитические функции»
13 июля 2011 г.
oracle: db file parallel read
db file parallel read
Кроме recovery, операция используется при buffer prefetching [опережающем чтении блоков данных] как оптимизация I/O (заменяя несколько одноблочных чтений (single-block reads))
Кроме recovery, операция используется при buffer prefetching [опережающем чтении блоков данных] как оптимизация I/O (заменяя несколько одноблочных чтений (single-block reads))
oracle: log file switch
log file switch
Ожидание переключения лог файлов по причине незаконченной операции checkpoint – записи процессом DBWR модифицированных блоков бд из кэша (buffer cache) на диск
Ожидание переключения лог файлов по причине незаконченной операции checkpoint – записи процессом DBWR модифицированных блоков бд из кэша (buffer cache) на диск
oracle: log file switch completion
log file switch completion
Ожидание завершения процесса переключения лог файлов (online redo logs), вероятная причина – неправильный (малый) размер online лог файлов (redo logs), недостаточное количество групп лог файлов (redo log groups)
Ожидание завершения процесса переключения лог файлов (online redo logs), вероятная причина – неправильный (малый) размер online лог файлов (redo logs), недостаточное количество групп лог файлов (redo log groups)
oracle: log file sync
log file sync
Пользовательский сессия (foreground process) ожидает совершения системным процессом (background process) LGWR операции записи модифицированных данных из лог буфера в redo log файл во время выполнения пользовательской сессией операции завершения транзакции COMMIT / ROLLBACK.
Ожидание может быть заметно в случае низкой скорости записи процессом LGWR или высокой конкуренции за системные ресурсы (диск, процессор). Типичные причины: неудачное размещение и [коственно] малый размер лог файлов (online redo logs), низкая производительность и/или неудачная конфигурация подсистемы ввода-вывода*), либо высокая (возможно, избыточная?) интенсивность операций COMMIT / ROLLBACK**.
Нормальное время ожидания не должно превышать нескольких миллисекунд для OLTP систем
*) Пример: несколько копий лог файлов (для «надёжности») на одном небыстром разделе RAID5 либо RAID6 (для «экономии»). Время ожидания может легко превышать и 20, и 30, и 80 ms. Oracle категорически не рекомендует RAID5 для размещения online redo log файлов
**) При невозможности изменить приложение с целью уменьшить частоту транзакций, для буферизации и выбора асинхронного режима можно рассмотреть изменение параметров COMMIT_WRITE (начиная с Oracle 10g) или COMMIT_LOGGING, COMMIT_WAIT (начиная с 11g)
WAITEVENT: «log file sync» Reference Note [ID 34592.1]:
Ожидание log file sync может состоит из следующих компонент:
Пользовательский сессия (foreground process) ожидает совершения системным процессом (background process) LGWR операции записи модифицированных данных из лог буфера в redo log файл во время выполнения пользовательской сессией операции завершения транзакции COMMIT / ROLLBACK.
Ожидание может быть заметно в случае низкой скорости записи процессом LGWR или высокой конкуренции за системные ресурсы (диск, процессор). Типичные причины: неудачное размещение и [коственно] малый размер лог файлов (online redo logs), низкая производительность и/или неудачная конфигурация подсистемы ввода-вывода*), либо высокая (возможно, избыточная?) интенсивность операций COMMIT / ROLLBACK**.
Нормальное время ожидания не должно превышать нескольких миллисекунд для OLTP систем
*) Пример: несколько копий лог файлов (для «надёжности») на одном небыстром разделе RAID5 либо RAID6 (для «экономии»). Время ожидания может легко превышать и 20, и 30, и 80 ms. Oracle категорически не рекомендует RAID5 для размещения online redo log файлов
**) При невозможности изменить приложение с целью уменьшить частоту транзакций, для буферизации и выбора асинхронного режима можно рассмотреть изменение параметров COMMIT_WRITE (начиная с Oracle 10g) или COMMIT_LOGGING, COMMIT_WAIT (начиная с 11g)
WAITEVENT: «log file sync» Reference Note [ID 34592.1]:
Ожидание log file sync может состоит из следующих компонент:
1. сессия пользователя посылает вызов системному процессу LGWR, который начинает обработку запроса, если не занят обработкой др.вызовов
2. LGWR собирает/готовит необходимые для записи redo данные и вызывает операцию ввода/вывода
3. операция записи log write
4. обработка результатов записи процессом LGWR
5. LGWR посылает сообщение пользовательской сессии сообщение о выполнении операции записи
6. сессия пользователя продолжает работу
2. LGWR собирает/готовит необходимые для записи redo данные и вызывает операцию ввода/вывода
3. операция записи log write
4. обработка результатов записи процессом LGWR
5. LGWR посылает сообщение пользовательской сессии сообщение о выполнении операции записи
6. сессия пользователя продолжает работу
Шаги 2 и 3 суммируются в статистике redo write time
Шаг 3 соответствует системному событию ожидания (Background Wait Events) log file parallel write
Шаги 5 и 6 могут занимать значительное время при увеличенной системной загрузке (load average) … после посылки сообщения пользовательскому процессу о завершении выполнения операции, ОС может потребоваться время до очередного запуска пользовательского процесса на выполнение…
Шаг 3 соответствует системному событию ожидания (Background Wait Events) log file parallel write
Шаги 5 и 6 могут занимать значительное время при увеличенной системной загрузке (load average) … после посылки сообщения пользовательскому процессу о завершении выполнения операции, ОС может потребоваться время до очередного запуска пользовательского процесса на выполнение…
oracle: direct path write / direct path write temp
direct path write / direct path write temp
Ожидание выполнения операции записи (write call) возникает, когда пользовательский процесс пишет блоки данных данные напрямую (directly) из PGA (в отличие от DBWR, пишущего на диск из buffer cache).
Direct path writes выполняется при след.операциях: дисковые сортировки (direct path write temp), параллельные DML, direct-path INSERTs, параллельные create table as select и некоторые операции с LOB
Аналогично direct path reads, количество ожиданий не обязательно совпадает с кол-вом запросов на запись в асинхронном режиме»
Соответствующая ожиданию статистика physical write direct
Ожидание выполнения операции записи (write call) возникает, когда пользовательский процесс пишет блоки данных данные напрямую (directly) из PGA (в отличие от DBWR, пишущего на диск из buffer cache).
Direct path writes выполняется при след.операциях: дисковые сортировки (direct path write temp), параллельные DML, direct-path INSERTs, параллельные create table as select и некоторые операции с LOB
Аналогично direct path reads, количество ожиданий не обязательно совпадает с кол-вом запросов на запись в асинхронном режиме»
Соответствующая ожиданию статистика physical write direct
oracle: direct path read / direct path read temp
Источник: Oracle mechanics
direct path read / direct path read temp
«Возникает при чтении пользовательским процессом данных с диска напрямую в PGA (в отличие от чтения в buffer cache SGA)
В синхронном режиме ввода-вывода каждое ожидание соответствует запросу на физическое чтение. При использовании асинхронного ввода-вывода, [пользовательский] процесс Oracle способен совмещать генерацию запросов на чтение данных с обработкой блоков, уже находящихся в PGA. [И только] когда процесс пытается получить доступ к блоку, который ещё не был прочитан с диска в PGA, генерируется вызов (wait call) и обновляется статистика этого события. Таким образом, количество ожиданий не обязательно совпадает с кол-вом запросов на чтение (в отличие от ожиданий db file scattered read и db file sequential read)
Документ How does Oracle load data into the buffer cache for table scans ? [ID 787373.1] описывает правила выбора метода сканирования «больших» таблиц (или разделения таблиц на большие и маленькие - smallness logic):
Соответствующая ожиданию статистика physical reads direct
direct path read / direct path read temp
«Возникает при чтении пользовательским процессом данных с диска напрямую в PGA (в отличие от чтения в buffer cache SGA)
В синхронном режиме ввода-вывода каждое ожидание соответствует запросу на физическое чтение. При использовании асинхронного ввода-вывода, [пользовательский] процесс Oracle способен совмещать генерацию запросов на чтение данных с обработкой блоков, уже находящихся в PGA. [И только] когда процесс пытается получить доступ к блоку, который ещё не был прочитан с диска в PGA, генерируется вызов (wait call) и обновляется статистика этого события. Таким образом, количество ожиданий не обязательно совпадает с кол-вом запросов на чтение (в отличие от ожиданий db file scattered read и db file sequential read)
Типичные ситуации возникновения ожидания:
- Сортировка большого (по сравнению с размером PGA или sort_area_size) объёма данных, после записи во временный сегмент, данные считываются с использованием операций direct path read temp
- Использование параллельные процессами (parallel slaves)
- Пользовательский серверный процесс обрабатывает данные в PGA быстрее, чем система ввода-вывода может считывать очередные блоки данных (buffers). Может быть индикатором недостаточной производительности ввода-вывода»
Scattered Read, Sequential Read, and Direct Path Read

Операция direct path read применяется при непараллельном сканировании больших таблиц – см. High ‘direct path read’ waits in 11g [ID 793845.1]: «Начиная с Oracle 11g произошли изменения правил при выборе между операциями direct path reads и чтением через buffer cache (ожидание db file scattered read) при сканировании таблиц [full table scan].
В версии 10g, сканирование «больших» таблиц выполнялось через буферный кэш (по умолчанию). В 11g, решение о выполнении чтения данных с использованием direct path или через буферный кэш основывается на размере таблицы, размере буферного кэша и др.статистиках.
Direct path reads быстрее, чем scattered reads и меньше влияет на производительность др.процессов, т.к. исключает конкуренцию за latches
В версии 10g, сканирование «больших» таблиц выполнялось через буферный кэш (по умолчанию). В 11g, решение о выполнении чтения данных с использованием direct path или через буферный кэш основывается на размере таблицы, размере буферного кэша и др.статистиках.
Direct path reads быстрее, чем scattered reads и меньше влияет на производительность др.процессов, т.к. исключает конкуренцию за latches
Документ How does Oracle load data into the buffer cache for table scans ? [ID 787373.1] описывает правила выбора метода сканирования «больших» таблиц (или разделения таблиц на большие и маленькие - smallness logic):
- Если кол-во блоков меньше или равно параметру _small_table_threshold Oracle сканирует объект через buffer cache, считая это более эффективным, чем использование direct read
- Любой объект (таблица) размером менее 2% буферного кэша будет сканироваться через buffer cache без использования direct load
В блоге Alex’а Fatkulin 11G adaptive direct path reads — what is the cached/dirty blocks threshold? можно найти исследование некоторых параметров, которые берутся в расчёт Oracle при выборе использования direct path read:
- размер (в блоках) таблицы ~ _small_table_threshold умноженный на 5
- cached blocks threshold – кол-во блоков таблицы, уже находящихся в буферном кэше SGA
- dirty blocks threshold- кол-во изменённых блоков таблицы, находящихся в буферном кэше SGA, не сброшенных на диск процессом DBWR
imho, по умолчанию, при старте инстанса параметр _small_table_threshold устанавливается ~ 1.9-2 % от размера буферного кэша [__]db_cache_size / db_block_size
Для форсированного включения direct path read в документах поддержки упоминается установка параметра _serial_direct_read=TRUE (доступно на уровне сессии, значение по умолчанию FALSE)
Для отключения Dion Cho Disabling direct path read for the serial full table scan– 11g нашёл и описал событие 10949:
$ oerr 10949 "Disable autotune direct path read for full table scan" // *Cause: // *Action: Disable autotune direct path read for serial full table scan. //
SQL> alter session set events '10949 trace name context forever, level 1';
Соответствующая ожиданию статистика physical reads direct
oracle: read by other session
Сессия ожидает блок данных, который в настоящий момент считывается в буферный кэш (buffer cache) другой сессией. До версии 10g событие учитывалось в группе ожиданий buffer busy wait.
Может случаться, например, когда две сессии делают full table scan в одно и то же время.
Алгоритм:
- блок не найден в буферном кэше
- читаем блок с диска
- выясняем что другая сессия уже читает блок с диска
- ждём пока другая сессия закончит чтение
Может случаться, например, когда две сессии делают full table scan в одно и то же время.
Алгоритм:
- блок не найден в буферном кэше
- читаем блок с диска
- выясняем что другая сессия уже читает блок с диска
- ждём пока другая сессия закончит чтение
12 июля 2011 г.
oracle: Cartesian Joins
http://aguppi.blogspot.com/2011/07/oracle-table-joins.html
cbo-access-path
«… используется в случае, когда одна или несколько таблиц не имеют никаких условий (join conditions) для соединения с другими таблицами запроса. Оптимизатор соединяет каждую строку первого источника данных с каждой строкой другого, создавая картезианское произведение (Cartesian product) двух наборов данных»
cbo-access-path
«… используется в случае, когда одна или несколько таблиц не имеют никаких условий (join conditions) для соединения с другими таблицами запроса. Оптимизатор соединяет каждую строку первого источника данных с каждой строкой другого, создавая картезианское произведение (Cartesian product) двух наборов данных»
SQL> select job, dname from emp cross join dept; SQL> select job, dname from emp, dept; ----------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 56 | 1008 | 10 (0)| 00:00:01 | | 1 | MERGE JOIN CARTESIAN| | 56 | 1008 | 10 (0)| 00:00:01 | | 2 | TABLE ACCESS FULL | DEPT | 4 | 40 | 3 (0)| 00:00:01 | | 3 | BUFFER SORT | | 14 | 112 | 7 (0)| 00:00:01 | | 4 | TABLE ACCESS FULL | EMP | 14 | 112 | 2 (0)| 00:00:01 | ----------------------------------------------------------------------------- SQL> select /*+ ORDERED*/ * from dept d, bonus b, emp e 2 where d.deptno = e.deptno 3 and b.ename = e.ename; ------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 96 | 10 (10)| 00:00:01 | |* 1 | HASH JOIN | | 1 | 96 | 10 (10)| 00:00:01 | | 2 | MERGE JOIN CARTESIAN| | 1 | 59 | 6 (0)| 00:00:01 | | 3 | TABLE ACCESS FULL | DEPT | 4 | 80 | 3 (0)| 00:00:01 | | 4 | BUFFER SORT | | 1 | 39 | 3 (0)| 00:00:01 | | 5 | TABLE ACCESS FULL | BONUS | 1 | 39 | 1 (0)| 00:00:01 | | 6 | TABLE ACCESS FULL | EMP | 14 | 518 | 3 (0)| 00:00:01 | -------------------------------------------------------------------------------
В последнем примере благодаря подсказке ORDERED оптимизатор первым делом соединяет таблицы DEPT и BONUS, не имеющих по условиям запроса никаких условий для соединения (join keys), следовательно, единственной возможной операцией оказывается Join Cartesian.
В случае, когда две небольшие таблицы (DEPT и BONUS) соединяются через условия d.deptno = e.deptno and b.ename = e.ename к «большой» таблице EMP и имеются дополнительные условия на столбцы небольших таблиц (фильтры dept.loc = ‘CHICAGO’ and bonus.comm > 30), оптимизатор по соображениям избирательности (selectivity) без всяких подсказок выбирает Merge Join Cartesian небольших таблиц с последующим соединением (Hash join) с большой таблицей:
SQL> exec dbms_stats.set_table_stats(ownname => 'SCOTT',tabname => 'EMP', numrows => 100000);
PL/SQL procedure successfully completed.
SQL> select * from dept d, bonus b, emp e
2 where d.deptno = e.deptno and d.loc = 'CHICAGO'
3 and b.ename = e.ename and b.comm > 30;
Execution Plan
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2381 | 174K| 16 (44)| 00:00:01 |
|* 1 | HASH JOIN | | 2381 | 174K| 16 (44)| 00:00:01 |
| 2 | MERGE JOIN CARTESIAN| | 1 | 38 | 6 (0)| 00:00:01 |
|* 3 | TABLE ACCESS FULL | DEPT | 1 | 18 | 3 (0)| 00:00:01 |
| 4 | BUFFER SORT | | 1 | 20 | 3 (0)| 00:00:01 |
|* 5 | TABLE ACCESS FULL | BONUS | 1 | 20 | 3 (0)| 00:00:01 |
| 6 | TABLE ACCESS FULL | EMP | 100K| 3613K| 8 (63)| 00:00:01 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("D"."DEPTNO"="E"."DEPTNO" AND "B"."ENAME"="E"."ENAME")
3 - filter("D"."LOC"='CHICAGO')
5 - filter("B"."COMM">30)Хинты
Можно использовать ORDERED
oracle: Sort Merge Joins
http://aguppi.blogspot.com/2011/07/oracle-table-joins.html
Sort Merge Joins (Oracle docs)
cbo-access-path
Sort merge joins используются для объединения строк из 2х независимых таблиц.
Sort merge joins успешно используется, когда в условиях соединения двух таблиц присутствуют операторы сравнения: <, <=, >, или >= , но не для операторов равества/неравества. Производительность sort merge joins лучше, чем у nested loop joins для больших наборов данных (data sets). [Также следует обратить внимание на то, что ] вы не можете использовать [более производительные операции] hash joins для соединения таблиц, если условия соединения отличаются от равенства (equality condition).
Sort merge joins лучше Hash Joins если:
Например, при использовании оператора сравнения «>» несвязанных столцов видим по одной операции SORT JOIN для каждой таблицы и объединённую операцию MERGE JOIN:
SQL> select * from emp e, dept d where e.empno > d.deptno;
Execution Plan
В случае с отсортироваными значениями одна из операций SORT JOIN исключается за ненадобностью:
SQL> select * from
2 (select empno from emp order by 1) e,
3 (select deptno from dept order by 1) d
4 where e.empno > d.deptno;
Execution Plan
Хинты
/*+ USE_MERGE( tab1 tab2) */
Sort Merge Joins (Oracle docs)
cbo-access-path
Sort merge joins используются для объединения строк из 2х независимых таблиц.
Sort merge joins успешно используется, когда в условиях соединения двух таблиц присутствуют операторы сравнения: <, <=, >, или >= , но не для операторов равества/неравества. Производительность sort merge joins лучше, чем у nested loop joins для больших наборов данных (data sets). [Также следует обратить внимание на то, что ] вы не можете использовать [более производительные операции] hash joins для соединения таблиц, если условия соединения отличаются от равенства (equality condition).
Sort merge joins лучше Hash Joins если:
- строки уже отсортированы
- операция сортировки не должна выполняться
- Sort join: Оба источника входных данных / таблицы сортируются по ключу соединения (join key).
- Merge join: Совместная обработка / объдинение (merging) отсортированных списков.
Например, при использовании оператора сравнения «>» несвязанных столцов видим по одной операции SORT JOIN для каждой таблицы и объединённую операцию MERGE JOIN:
SQL> select * from emp e, dept d where e.empno > d.deptno;
Execution Plan
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 56 | 3192 | 6 (17)| 00:00:01 |
| 1 | MERGE JOIN | | 56 | 3192 | 6 (17)| 00:00:01 |
| 2 | SORT JOIN | | 14 | 518 | 2 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| EMP | 14 | 518 | 2 (0)| 00:00:01 |
| 4 | INDEX FULL SCAN | PK_EMP | 14 | | 1 (0)| 00:00:01 |
|* 5 | SORT JOIN | | 4 | 80 | 4 (25)| 00:00:01 |
| 6 | TABLE ACCESS FULL | DEPT | 4 | 80 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access(INTERNAL_FUNCTION("E"."EMPNO")>INTERNAL_FUNCTION("D"."DEPTNO"))
filter(INTERNAL_FUNCTION("E"."EMPNO")>INTERNAL_FUNCTION("D"."DEPTNO"))В случае с отсортироваными значениями одна из операций SORT JOIN исключается за ненадобностью:
SQL> select * from
2 (select empno from emp order by 1) e,
3 (select deptno from dept order by 1) d
4 where e.empno > d.deptno;
Execution Plan
------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 56 | 896 | 3 (34)| 00:00:01 |
| 1 | MERGE JOIN | | 56 | 896 | 3 (34)| 00:00:01 |
| 2 | INDEX FULL SCAN | PK_DEPT | 4 | 12 | 1 (0)| 00:00:01 |
|* 3 | SORT JOIN | | 14 | 182 | 2 (50)| 00:00:01 |
| 4 | VIEW | | 14 | 182 | 1 (0)| 00:00:01 |
| 5 | INDEX FULL SCAN| PK_EMP | 14 | 56 | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("E"."EMPNO">"DEPTNO")
filter("E"."EMPNO">"DEPTNO")Хинты
/*+ USE_MERGE( tab1 tab2) */
11 июля 2011 г.
oracle: hash Joins
http://aguppi.blogspot.com/2011/07/oracle-table-joins.html
Hash Joins (Oracle docs)
Hash Joins используются для объединения больших наборов данных.
Оптимизатор выбирает меньшую таблицу и создает хеш-таблицу для ключа объединения в памяти. Затем он просматривает другую таблицу(большую) и проверяет хеш таблицу в памяти на совпадения с ней.
Hash Join Hint
/*+ USE_HASH(tab1 tab2)*/
Hash Joins (Oracle docs)
Hash Joins используются для объединения больших наборов данных.
Оптимизатор выбирает меньшую таблицу и создает хеш-таблицу для ключа объединения в памяти. Затем он просматривает другую таблицу(большую) и проверяет хеш таблицу в памяти на совпадения с ней.
Hash Join Hint
/*+ USE_HASH(tab1 tab2)*/
SELECT /*+use_hash(employees departments)*/ * FROM employees, departments WHERE employees.department_id = departments.department_id;
8 июля 2011 г.
oracle: Nested Loop Joins
http://aguppi.blogspot.com/2011/07/oracle-table-joins.html
Nested Loop Joins (Oracle docs)
Nested Loops (объединения с вложенными циклами) - читает строку из 1й таблицы(ведущая таблица - outer table), и затем сравнивает всю 2ю таблицу(ведомая таблица - inner table) на совпадение, затем берёт следующую строку из 1й таблицы и опять сравнивает всю 2ю таблицу на совпадение и т.д.
Nested Loops hint
Используем хинт /*+ USE_NL*/, можно в связке с ORDERED, чтобы гарантировать нужный порядок обращения к таблицам.
Nested Loops быстро извлекают 1е несколько строк результирующего множества, но по общему времени выполнения Hash Joins быстрее. Этим свойством можно воспользоваться, когда пользователю нужно быстро получить 1е несколько строк, не дожидаясь всего результата.
В плане выполнения сначала идёт цикл по 1й таблице(outer loop) , а потом по 2й (inner loop)
В этом примере outer loop сначала получает все строки из таблицы EMPLOYEES, а затем для каждого сотрудника inner loop получает соответствующие строки из таблицы JOBS.
Nested Loops идеален, если 1я таблица маленькая, и объединённые столбцы проиндексированы уникально или этот индекс высоко избирательный.
Строка из 1й таблицы обычно получается из index scan или full table scan, а из 2й таблицы было бы идеально, чтобы строка выбиралась с помощью index scan.
Nested Loop Joins (Oracle docs)
Nested Loops (объединения с вложенными циклами) - читает строку из 1й таблицы(ведущая таблица - outer table), и затем сравнивает всю 2ю таблицу(ведомая таблица - inner table) на совпадение, затем берёт следующую строку из 1й таблицы и опять сравнивает всю 2ю таблицу на совпадение и т.д.
Nested Loops hint
Используем хинт /*+ USE_NL*/, можно в связке с ORDERED, чтобы гарантировать нужный порядок обращения к таблицам.
SELECT /*+ ORDERED USE_NL(customers) to get first row faster */ accounts.balance, customers.last_name, customers.first_name FROM accounts, customers WHERE accounts.customer_id = customers.customer_id;
SELECT /*+ USE_NL(l h) */ h.customer_id, l.unit_price * l.quantity FROM orders h ,order_items l WHERE l.order_id = h.order_id;
Nested Loops быстро извлекают 1е несколько строк результирующего множества, но по общему времени выполнения Hash Joins быстрее. Этим свойством можно воспользоваться, когда пользователю нужно быстро получить 1е несколько строк, не дожидаясь всего результата.
В плане выполнения сначала идёт цикл по 1й таблице(outer loop) , а потом по 2й (inner loop)
NESTED LOOPSouter_loopinner_loop
...
| 2 | NESTED LOOPS | | 3 | 141 | 7 (15)|
|* 3 | TABLE ACCESS FULL | EMPLOYEES | 3 | 60 | 4 (25)|
| 4 | TABLE ACCESS BY INDEX ROWID| JOBS | 19 | 513 | 2 (50)|
|* 5 | INDEX UNIQUE SCAN | JOB_ID_PK | 1 | | |
... В этом примере outer loop сначала получает все строки из таблицы EMPLOYEES, а затем для каждого сотрудника inner loop получает соответствующие строки из таблицы JOBS.
Nested Loops идеален, если 1я таблица маленькая, и объединённые столбцы проиндексированы уникально или этот индекс высоко избирательный.
Строка из 1й таблицы обычно получается из index scan или full table scan, а из 2й таблицы было бы идеально, чтобы строка выбиралась с помощью index scan.
oracle: Избирательность индекса
В представлении USER_INDEXES есть столбец distinct_keys, который содержит кол-во уникальных ключей для этого индекса. Сравнение distinct_keys и числа строк в таблице позволяет определить избирательность индекса. Чем ближе distinct_keys к числу строк в таблице, тем более избирательный индекс, запрос с использованием этого индекса вернёт меньшее кол-во строк, сообтветсвенно быстрее отработает запрос. Но при использовании дополнительных индексов (сложные/сцепленные индексы) в запросе издержки могут превысить выгоду.
6 июля 2011 г.
oracle: sga_target
SGA_TARGET
| Property | Description |
|---|---|
| Parameter type | Big integer |
| Syntax | SGA_TARGET = integer [K | M | G] |
| Default value | 0 (SGA autotuning is disabled) |
| Modifiable | ALTER SYSTEM |
| Range of values | 64 to operating system-dependent |
| Basic | Yes |
SGA_TARGET specifies the total size of all SGA components. If SGA_TARGET is specified, then the following memory pools are automatically sized:- Buffer cache (
DB_CACHE_SIZE)
- Shared pool (
SHARED_POOL_SIZE)
- Large pool (
LARGE_POOL_SIZE)
- Java pool (
JAVA_POOL_SIZE)
- Streams pool (
STREAMS_POOL_SIZE)
The following pools are manually sized components and are not affected by Automatic Shared Memory Management:
- Log buffer
- Other buffer caches, such as
KEEP,RECYCLE, and other block sizes
- Fixed SGA and other internal allocations
oracle: sga_max_size
SGA_MAX_SIZE
| Property | Description |
|---|---|
| Parameter type | Big integer |
| Syntax | SGA_MAX_SIZE = integer [K | M | G] |
| Default value | Initial size of SGA at startup, dependent on the sizes of different pools in the SGA, such as buffer cache, shared pool, large pool, and so on. |
| Modifiable | No |
| Range of values | 0 to operating system-dependent |
SGA_MAX_SIZE specifies the maximum size of the SGA for the lifetime of the instance.
5 июля 2011 г.
oracle: sql условие EXISTS
Условие EXISTS и проверка существования набора значений в ORACLE SQL
Условие EXISTS используется только в одной ситуации — когда вы используете в запросе и подзапрос и хотите проверить, возвращает ли подзапрос записи. Если подзапрос возвращает хотя бы одну запись, то условие EXISTS вернет True, если нет — то False.
Пример применения этого условия может выглядеть так:
В этом примере мы возвращаем информацию о всех департаментах, для которых в таблице employees есть сотрудники.
Этот запрос можно переписать с помощью конструкции IN:
Как обычно, это условие EXISTS можно обращать при помощи NOT:
Те же возможности предусмотрены и для Microsoft SQL Server.
Условие EXISTS используется только в одной ситуации — когда вы используете в запросе и подзапрос и хотите проверить, возвращает ли подзапрос записи. Если подзапрос возвращает хотя бы одну запись, то условие EXISTS вернет True, если нет — то False.
Пример применения этого условия может выглядеть так:
SELECT * FROM departments d WHERE EXISTS
(SELECT * FROM employees e WHERE d.department_id = e.department_id);
(SELECT * FROM employees e WHERE d.department_id = e.department_id);
В этом примере мы возвращаем информацию о всех департаментах, для которых в таблице employees есть сотрудники.
Этот запрос можно переписать с помощью конструкции IN:
SELECT *
FROM users
WHERE users.ID IN (SELECT users_id
FROM users_res
WHERE users.ID = users_res.users_id AND users_res.ID > 1);
FROM users
WHERE users.ID IN (SELECT users_id
FROM users_res
WHERE users.ID = users_res.users_id AND users_res.ID > 1);
Как обычно, это условие EXISTS можно обращать при помощи NOT:
SELECT * FROM departments d WHERE NOT EXISTS
(SELECT * FROM employees e WHERE d.department_id = e.department_id);
(SELECT * FROM employees e WHERE d.department_id = e.department_id);
Те же возможности предусмотрены и для Microsoft SQL Server.
wget
Нужно скачать много файлов шаблона file_NNN.ext с одного места.
На perl пишем скрипт:
Получаем файл со ссылками files.txt
Далее тянем их при помощи wget:
На perl пишем скрипт:
open (MYFILE, '>>files.txt');
for ($count = 500; $count < 600; $count++) {
print MYFILE "http://www.url.net/files/".$count.".ext\n" ;
}
close (MYFILE);
for ($count = 500; $count < 600; $count++) {
print MYFILE "http://www.url.net/files/".$count.".ext\n" ;
}
close (MYFILE);
Получаем файл со ссылками files.txt
Далее тянем их при помощи wget:
wget -c -i files.ext
oracle: Tables Joins (объединения таблиц)
Из Oracle9i Database Performance Tuning Guide and Reference Release 2 (9.2) Understanding Joins
CBO access path
Виды соединений:
Nested Loop Joins
Hash Joins
Sort Merge Joins
Cartesian Joins
Outer Joins
Как оптимизатор выбирает метод соединения
Оптимизатор оценивает стоимость каждого метода и выбирает самый дешёвый из них.
Как оптимизатор выбирает Execution Plan (план выполнения)
Оптимизатор должен решить в каком порядке соединять таблицы, т.е. какая таблица будет 1й, 2й и т.д.
Если нужно указать порядок соединения вручную, то используется хинт ORDERED (/*+ ORDERED */), тогда соединение осуществляется в том порядке, в котором указаны таблицы после from.
Например: select /*+ ORDERED*/ col1, col2, col3, col4 from t1, t2, t3
Это одинаково для CBO и RBO:
CBO access path
Виды соединений:
Nested Loop Joins
Hash Joins
Sort Merge Joins
Cartesian Joins
Outer Joins
Как оптимизатор выбирает метод соединения
Оптимизатор оценивает стоимость каждого метода и выбирает самый дешёвый из них.
- Nested Loop Joins обычно не эффективен при соединении большого кол-ва строк (обычно более 10 000 строк уже много). Стоимость Nested Loop Joins рассчитывается по формуле:
cost= access cost of A + (access cost of B * number of rows from A)
- Hash Joins эффективны для большого кол-ва строк. Стоимость Hash Joins рассчитывается по формуле:
cost= (access cost of A * number of hash partitions of B) + access cost of B
- При использовании RBO оптимизатора эффективны Merge Joins. Стоимость Merge Joins рассчитывается по формуле:
cost= access cost of A + access cost of B +(sort cost of A + sort cost of B)
Если данные уже отсортированы, то стоимость сортировки равна нулю.
Как оптимизатор выбирает Execution Plan (план выполнения)
Оптимизатор должен решить в каком порядке соединять таблицы, т.е. какая таблица будет 1й, 2й и т.д.
Если нужно указать порядок соединения вручную, то используется хинт ORDERED (/*+ ORDERED */), тогда соединение осуществляется в том порядке, в котором указаны таблицы после from.
Например: select /*+ ORDERED*/ col1, col2, col3, col4 from t1, t2, t3
Это одинаково для CBO и RBO:
- Оптимизатор определяет какая из таблиц вернёт не более чем одну строку основываясь на ограничениях
UNIQUEиPRIMARYKEYдля таблицы. Если такая ситуация действительна, то оптимизатор ставит эту таблицу на первое место в соединении - For join statements with outer join conditions, the table with the outer join operator must come after the other table in the condition in the join order. The optimizer does not consider join orders that violate this rule.
With the CBO, the optimizer generates a set of execution plans, according to possible join orders, join methods, and available access paths. The optimizer then estimates the cost of each plan and chooses the one with the lowest cost. The optimizer estimates costs in the following ways:
- The cost of a nested loops operation is based on the cost of reading each selected row of the outer table and each of its matching rows of the inner table into memory. The optimizer estimates these costs using the statistics in the data dictionary.
- The cost of a sort merge join is based largely on the cost of reading all the sources into memory and sorting them.
oracle: Sample Table Scans
http://aguppi.blogspot.com/2011/06/oracle-access-path.html
A sample table scan retrieves a random sample of data from a table. This access path is used when a statement's
FROM clause includes the SAMPLE clause or the SAMPLE BLOCK clause. To perform a sample table scan when sampling by rows (the SAMPLE clause), Oracle reads a specified percentage of rows in the table. To perform a sample table scan when sampling by blocks (the SAMPLE BLOCK clause), Oracle reads a specified percentage of table blocks.Oracle does not support sample table scans when the query involves a join or a remote table. However, you can perform an equivalent operation by using a
CREATE TABLE AS SELECT query to materialize a sample of an underlying table. You then rewrite the original query to refer to the newly created table sample. Additional queries can be written to materialize samples for other tables. Sample table scans require the CBO.Example 1-13 uses a sample table scan to access 1% of the
employees table, sampling by blocks.Example 1-13 Sample Table Scan
SELECT * FROM employees SAMPLE BLOCK (1);
The
EXPLAIN PLAN output for this statement might look like this:------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| ------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 68 | 3 (34)| | 1 | TABLE ACCESS SAMPLE | EMPLOYEES | 1 | 68 | 3 (34)| -------------------------------------------------------------------------
oracle: Hash Scans
http://aguppi.blogspot.com/2011/06/oracle-access-path.html
A hash scan is used to locate rows in a hash cluster, based on a hash value. In a hash cluster, all rows with the same hash value are stored in the same data block. To perform a hash scan, Oracle first obtains the hash value by applying a hash function to a cluster key value specified by the statement. Oracle then scans the data blocks containing rows with that hash value.
A hash scan is used to locate rows in a hash cluster, based on a hash value. In a hash cluster, all rows with the same hash value are stored in the same data block. To perform a hash scan, Oracle first obtains the hash value by applying a hash function to a cluster key value specified by the statement. Oracle then scans the data blocks containing rows with that hash value.
oracle: Cluster Scans
http://aguppi.blogspot.com/2011/06/oracle-access-path.html
A cluster scan is used to retrieve, from a table stored in an indexed cluster, all rows that have the same cluster key value. In an indexed cluster, all rows with the same cluster key value are stored in the same data block. To perform a cluster scan, Oracle first obtains the rowid of one of the selected rows by scanning the cluster index. Oracle then locates the rows based on this rowid.
A cluster scan is used to retrieve, from a table stored in an indexed cluster, all rows that have the same cluster key value. In an indexed cluster, all rows with the same cluster key value are stored in the same data block. To perform a cluster scan, Oracle first obtains the rowid of one of the selected rows by scanning the cluster index. Oracle then locates the rows based on this rowid.
Подписаться на:
Сообщения (Atom)