http://aguppi.blogspot.com/2011/07/oracle-table-joins.html
Sort Merge Joins (Oracle docs)
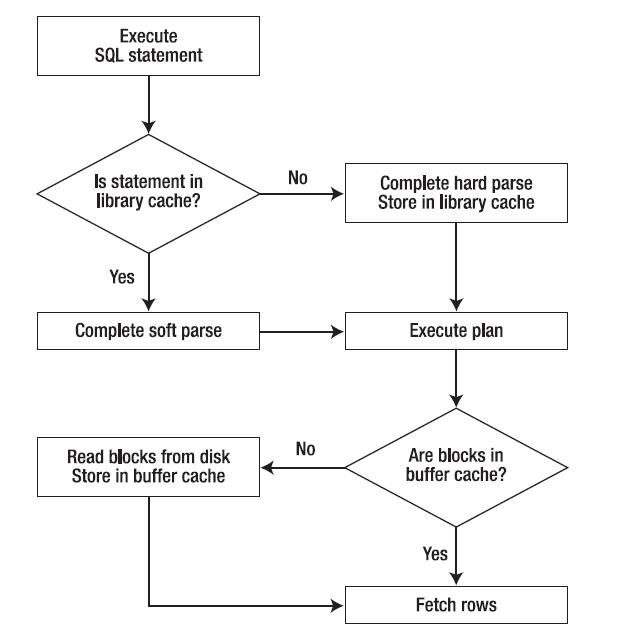
cbo-access-path
Sort merge joins используются для объединения строк из 2х независимых таблиц.
Sort merge joins успешно используется, когда в условиях соединения двух таблиц присутствуют операторы сравнения: <, <=, >, или >= , но не для операторов равества/неравества. Производительность
sort merge joins лучше, чем у
nested loop joins для больших наборов данных (
data sets). [Также следует обратить внимание на то, что ] вы не можете использовать [более производительные операции]
hash joins для соединения таблиц, если условия соединения отличаются от равенства (
equality condition).
Sort merge joins лучше Hash Joins если:
- строки уже отсортированы
- операция сортировки не должна выполняться
При выполнении операции merge join отсутствует концепция ведущей (
driving table) / ведомой таблицы.
Sort merge joins состоит из 2х шагов:
- Sort join: Оба источника входных данных / таблицы сортируются по ключу соединения (join key).
- Merge join: Совместная обработка / объдинение (merging) отсортированных списков.
Sort merge joins может использоваться для соединений с условиями отличными от равенства ( <, <=, >, >= , но не для операторов равества/неравества ),
чего не позволяет Hash Joins.
Например, при использовании оператора сравнения «>» несвязанных столцов видим по одной операции SORT JOIN для каждой таблицы и объединённую операцию MERGE JOIN:
SQL> select * from emp e, dept d where e.empno > d.deptno;
Execution Plan
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 56 | 3192 | 6 (17)| 00:00:01 |
| 1 | MERGE JOIN | | 56 | 3192 | 6 (17)| 00:00:01 |
| 2 | SORT JOIN | | 14 | 518 | 2 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| EMP | 14 | 518 | 2 (0)| 00:00:01 |
| 4 | INDEX FULL SCAN | PK_EMP | 14 | | 1 (0)| 00:00:01 |
|* 5 | SORT JOIN | | 4 | 80 | 4 (25)| 00:00:01 |
| 6 | TABLE ACCESS FULL | DEPT | 4 | 80 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access(INTERNAL_FUNCTION("E"."EMPNO")>INTERNAL_FUNCTION("D"."DEPTNO"))
filter(INTERNAL_FUNCTION("E"."EMPNO")>INTERNAL_FUNCTION("D"."DEPTNO"))
В случае с отсортироваными значениями одна из операций SORT JOIN исключается за ненадобностью:
SQL> select * from
2 (select empno from emp order by 1) e,
3 (select deptno from dept order by 1) d
4 where e.empno > d.deptno;
Execution Plan
------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 56 | 896 | 3 (34)| 00:00:01 |
| 1 | MERGE JOIN | | 56 | 896 | 3 (34)| 00:00:01 |
| 2 | INDEX FULL SCAN | PK_DEPT | 4 | 12 | 1 (0)| 00:00:01 |
|* 3 | SORT JOIN | | 14 | 182 | 2 (50)| 00:00:01 |
| 4 | VIEW | | 14 | 182 | 1 (0)| 00:00:01 |
| 5 | INDEX FULL SCAN| PK_EMP | 14 | 56 | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("E"."EMPNO">"DEPTNO")
filter("E"."EMPNO">"DEPTNO")
Хинты
/*+ USE_MERGE( tab1 tab2) */